First Time Scraping Webpage? These Tools Might Save Your Day
- 1 Top 10 Scraping Webpage Tools
- 1.1 R (Programming Language)
- 1.2 Beautiful Soup
- 1.3 Scrapy
- 1.4 Selenium
- 1.5 ParseHub
- 1.6 Octoparse
- 1.7 Puppeteer
- 1.8 PyQuery
- 2 9. Apify
- 3 10. Import.io
- 4 Conclusion
The process of extracting data from websites has become one of the most essential tools in the age of big data. This process is called data scraping, and it’s an invaluable skill for many professionals, from market researchers to data scientists.
Whether you’re looking to gather information or gain insights from a vast amount of data, web scraping is just the tool you need.
For a newbie, web scraping may seem daunting at first. Thankfully, there are several user-friendly tools that offer different approaches to extracting data from websites, catering to a wide range of needs and technical expertise.
Top 10 Scraping Webpage Tools
Let’s discuss the ten best tools that can save the day and make your first-time web scraping experience a breeze.
R (Programming Language)

R is a powerful programming language and environment widely used for statistical computing and data analysis. While not specifically designed for web scraping, R provides several tools that make it a popular choice for extracting data from websites.
If you want to go web scraping with R, you’ll get powerful and user-friendly solutions from the rest package for data extraction. For instance, it allows you to select specific elements and extract their content using CSS selectors.
Plus, it gives you unique functions to navigate through HTML structures, select specific elements, and extract data based on patterns or attributes. So you can retrieve text, URLs, tables, and other content from web pages without hassle.
Beautiful Soup

Beautiful Soup is a Python library that simplifies web scraping by providing an easy-to-use interface for parsing HTML and XML documents. It handles poorly formatted HTML gracefully, making it a great choice for scraping websites with inconsistent markup.
One of the key features of BeautifulSoup is its ability to search for specific elements or extract desired information using CSS selectors or XPath expressions. It enables you to extract text, retrieve attribute values, or even navigate to parent or sibling elements.
To start using Beautiful Soup, you need to install it using pip, the Python package installer. Once installed, you can import it into your Python script and begin parsing HTML or XML documents.
With a wide range of functions and methods, Beautiful Soup is a nice tool to have while scraping data from websites.
Scrapy

Scrapy is a popular Python framework that is specifically designed for web scraping. It has a high-level API that makes it easier to build web spiders, which are scripts that navigate websites and extract data. By using Scrapy, you can scrape large amounts of data from multiple pages without any complications.
One of the key features of Scrapy is its ability to handle asynchronous requests, which helps you to scrape multiple pages simultaneously.
This can speed up the scraping process significantly, especially when dealing with numerous URLs or websites. It also supports various middleware and pipelines, enabling you to handle cookies, user agents, and data storage efficiently. While Scrapy might have a steeper learning curve compared to other tools, it is an excellent choice for complex web scraping projects.
Selenium

Selenium is another popular web automation tool that can also be used for web scraping.
Unlike Beautiful Soup and Scrapy, Selenium is a browser automation tool that lets you interact with web pages in a more human-like manner. It can simulate clicks, form submissions, and JavaScript execution, making it ideal for scraping websites with dynamic content.
Selenium supports multiple web browsers, such as Chrome, Firefox, and Safari, through its WebDriver interface. You can initiate a browser instance using Selenium WebDriver, load web pages, execute JavaScript, and extract desired information from the rendered content.
One of the key advantages of Selenium is its ability to handle websites that heavily rely on JavaScript for content generation.
By waiting for JavaScript to execute and render the page, Selenium can scrape data from dynamically generated elements. This makes it a very useful tool you can apply for scraping modern web applications.
ParseHub

ParseHub is a user-friendly web scraping tool that offers a point-and-click interface for extracting data from websites. It eliminates the need to write code and allows non-programmers to scrape data easily.
Once you installed ParseHub, you can open a webpage and interact with it using the point-and-click interface. You can select elements on the page, define how the data should be extracted, and set up pagination to scrape multiple pages if needed.
ParseHub automatically detects patterns in the web page and extracts data based on your instructions. It can handle nested elements, extract text, images, and tables, or even click on elements to access more data. Once the scraping process is complete, you can export the data in various formats, such as CSV or JSON.
ParseHub is a great choice if you prefer a visual approach to web scraping or don’t have programming experience. It simplifies the scraping process and eases the process of getting started quickly.
Octoparse
Octoparse is another user-friendly tool for web scraping, but the biggest advantage is that this tool doesn’t require any coding knowledge. It provides a desktop application with a graphical interface, which makes it accessible to users without programming skills.
The tool supports static and dynamic websites, making it suitable for various scraping tasks. You can select data points to extract using its point-and-click interface and define extraction rules to scrape data from multiple pages.
Octoparse provides advanced features such as handling AJAX requests, filling out forms, and extracting data from dropdown menus. It also offers scheduling options, allowing you to automate scraping tasks at specified times or intervals.
It also has cloud extraction, enabling you to run scraping tasks on their servers and retrieve the results conveniently.
Puppeteer

Puppeteer is a Node.js library that can be used for web scraping by leveraging its ability to render dynamic content and extract data from websites.
Its key feature is its ability to run a full instance of a headless Chrome browser. This means it can handle websites that heavily rely on JavaScript for rendering and interactivity. That’s why it’s the perfect choice for scraping modern web applications and single-page applications (SPAs).
You get high-level API that can help you control both headless Chrome and Chromium browsers, automating browser actions like navigation, form submission, and JavaScript execution.
Using Puppeteer, you can simulate user interactions with a website, such as clicking buttons, filling out forms, and scrolling through pages. It can also generate screenshots and PDF files of web pages, which can be quite useful for data visualization.
PyQuery
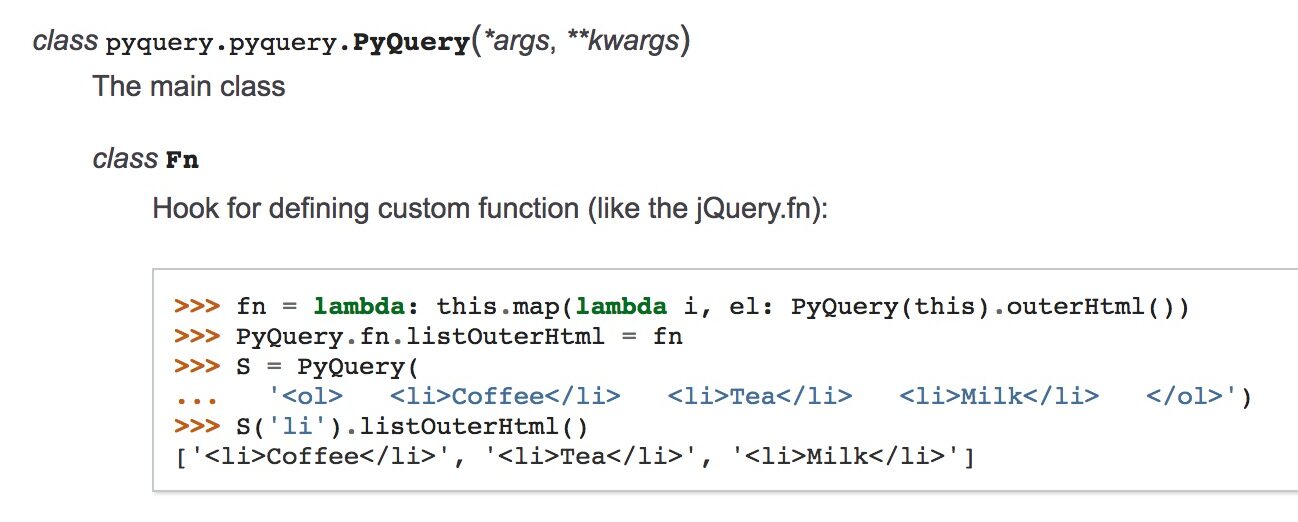
PyQuery is a Python library that brings jQuery-like syntax and functionality to web scraping. With this tool, you can parse HTML documents and manipulate them using familiar jQuery methods.
If you are already familiar with jQuery, you’ll love PyQuery because of its seamless transition to web scraping in Python.
With PyQuery, you can load HTML documents and query specific elements using CSS selectors. Furthermore, it also provides a concise and expressive way to interact with HTML documents, similar to how you would use jQuery in JavaScript.
PyQuery has powerful features such as filtering, slicing, and applying regular expressions to extracted data. It integrates well with other Python libraries, allowing you to combine it with tools like pandas for data analysis and manipulation.
9. Apify
Apify is a platform with a variety of tools and services for web scraping, including a web-based scraper and a cloud-based infrastructure. This tool is designed to simplify the process of web scraping, making it easier for both beginners and experienced developers.
The Apify web-based scraper provides a point-and-click interface for building scraping agents without writing code. You can navigate to a webpage, select data points to extract, and set up rules to define the scraping process.
The scraper automatically detects patterns in the web page and generates extraction rules for scraping multiple pages.
Apify also offers the Apify SDK, a JavaScript-based library for building custom web scraping solutions. The SDK has several tools for handling web requests, parsing HTML, managing proxies, and scheduling scraping tasks.
10. Import.io
Import.io is a web scraping platform that offers users both a web-based tool and an API for extracting data from websites.
The web-based tool can help you create scraping agents by visually selecting data points on web pages. It automatically detects patterns and generates extraction rules for scraping multiple pages.
Import.io also lets developers use its API to integrate web scraping functionality into their own applications. The API enables programmatic access to web scraping features, allowing you to build custom scraping workflows and retrieve data in a structured format.
Conclusion
Web scraping is a valuable technique that can open up a world of possibilities for gathering and analyzing data from the web.
When scraping a webpage for the first time, it’s normal to get overwhelmed and make some mistakes. But with these tools mentioned above, you can confidently start your web scraping journey, even if you’re a beginner.
So, roll up your sleeves, choose the tool that suits you best, and dive into the exciting world of web scraping!